

Consider for a moment the product teams, the product-and-engineering division, and the organization itself that we work with. Their goal is not to "do research." The goal at each level of scale is to make timely and effective decisions, reducing our cycle times through contextual awareness and insight. The idea of strategic agility will become increasingly important: we are entering a world where the time and cost of software production decrease by orders of magnitude. As software production is commoditized (every other competitor also speeds up) the cadence of our strategy cycle at each level of organizational scale, how we learn and act and decide, becomes increasingly critical.
Continuous discovery and consolidated insight
This is one reason product teams doing direct customer discovery work can outmaneuver teams that work in formal, project-based research cycles — for a while, at least. Continuous discovery doesn't obviate the need for structured research activities, it shifts how and where research effort is best deployed. Work in a continuous discovery mode surfaces a mix of inward-looking product insight, as well as external information about users' reality. That external information tends to get stripped of context and stored in bets, backlogs, opportunity-solution trees, or product boards.
What's missing is a means of consolidating user understanding into shared knowledge that can bring the rest of the team along. We need some means of taking this fast-cycle learning output and building an accretive collection of contextual awareness that can be transmitted and built upon. Last time, in Growing Research in Product Organizations, I wrote:
A sharp researcher with a grounding in product should be able to form, quite quickly, a rough-idea outline of which user journeys, goals, scenarios, power structures, and workflows that a product’s existence implies (and depends on.)
This kind of thinking isn't limited to researchers—it benefits deeply from the perspective of product, the visual skills of design, and the technical reality of engineering—but I believe it's the place that research can play in an environment where research-as-specialization is losing traction.
This is today's starting assumption: what research work in a product context can and arguably should look like. In this vein, I propose a kind of model-first thinking for research activities, in an attempt to build research as a stream-aligned activity and unbundle it from rigid project structures. I also contend that a lot of our activities, right now, may lead to wasted work if we don't first start by structuring internal knowledge — to see if there's really a productive pathway forward for external research in a given domain.
Visual maps and models, iterative adaptation
We begin with a rough set of the models or artifacts to sketch implied by our scope of work and build out an ongoing stream of work to bring that model and its attendant edges and implications up to a useful fidelity for the team to work with. And we try to build the highest-fidelity version of a given model — journey map, user segmentation 2x2, storyboard, Wardley map, and so on — from internal knowledge first.
Visually modeling internal assumptions increases credibility, trust, participation, and access to users, when operated effectively. The technical aspects of modeling assumptions and insight become easier when we have a set of potential models to pull off the shelf. The human work, effectively shepherding a shared hypothesis about reality with clear implications for ongoing or upcoming work, is the crux of the challenge.
This is why visual models are our preferred tool of choice, to start: making assumptions visibly "tangible" allows them to be discussed, challenged, and built upon in a way that text and story cannot. This kind of engagement allows for a living, adaptive artifact of understanding that keeps the team involved as inquiry moves from internal hypotheses to external engagement.
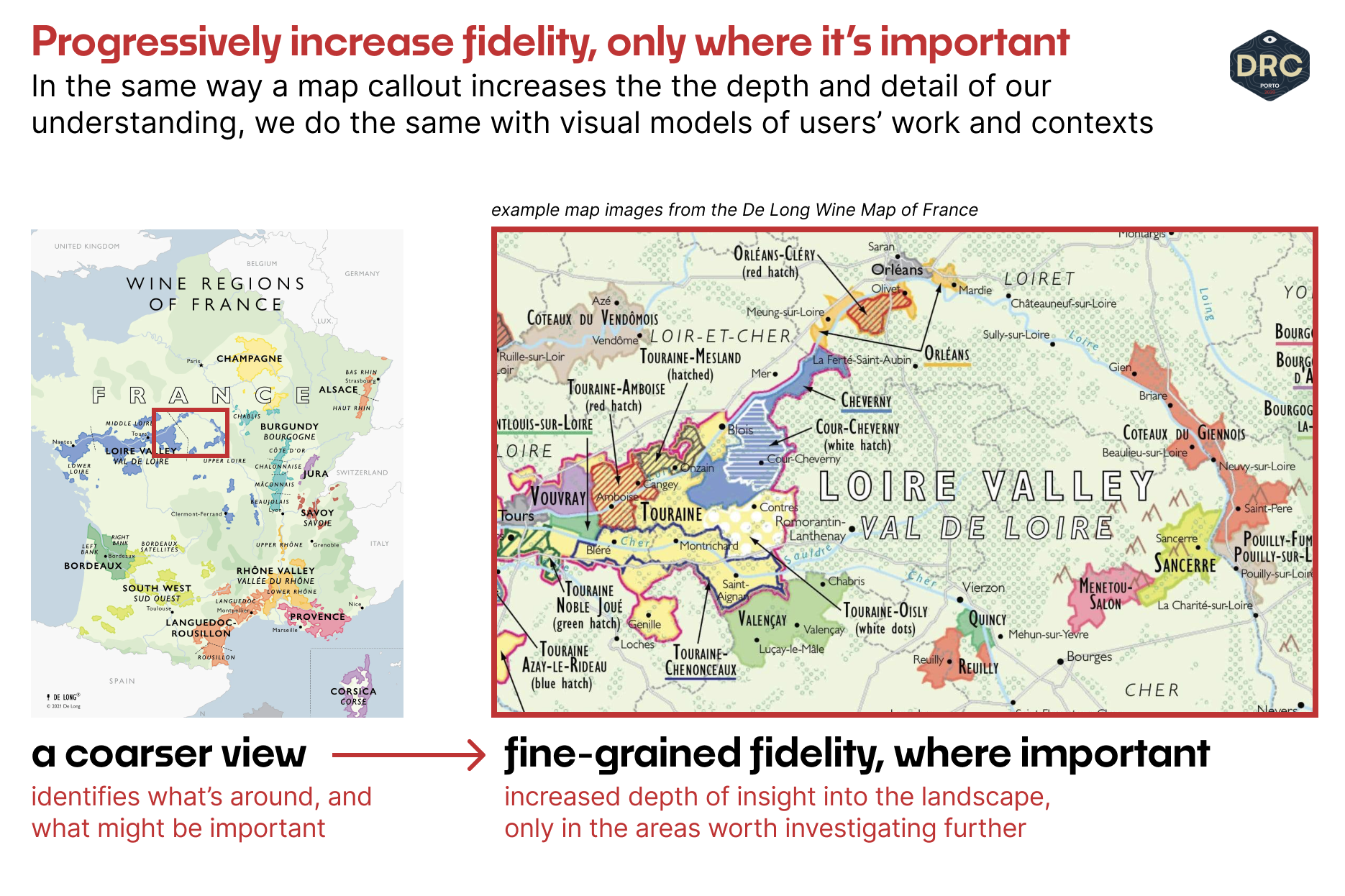
As we begin to explore from an internally-informed starting point, there is a near-infinite depth available for us to explore — our understanding of the world and how we visualize it will evolve dramatically. I like to think of this increase in fidelity in the same way that real-world maps have a rough characterization of the larger landscape, but depth where it's interesting (like when you're trying to work out where the Loire Valley white wines are based on Chenin Blanc vs. Sauvignon Blanc, for example.)
An off-the-shelf menu of models will help us figure out where and how to look. The first move, then, is to build a coarse view, internally, of the most important kind of user-reality models we need to drive the product work forward; we sketch them out, draw out the boundaries of what we think is the most important, and then begin, iteratively, to layer in the fidelity-of-insight and nuance that will help push our work forward.
Model menu and scoping criteria
Here's a small set of starting models, in the chart below. We can think through these models as a means of visualizing different aspects of the user reality from fine-grained actions down to the broad forces of context that drive them and everything in between.
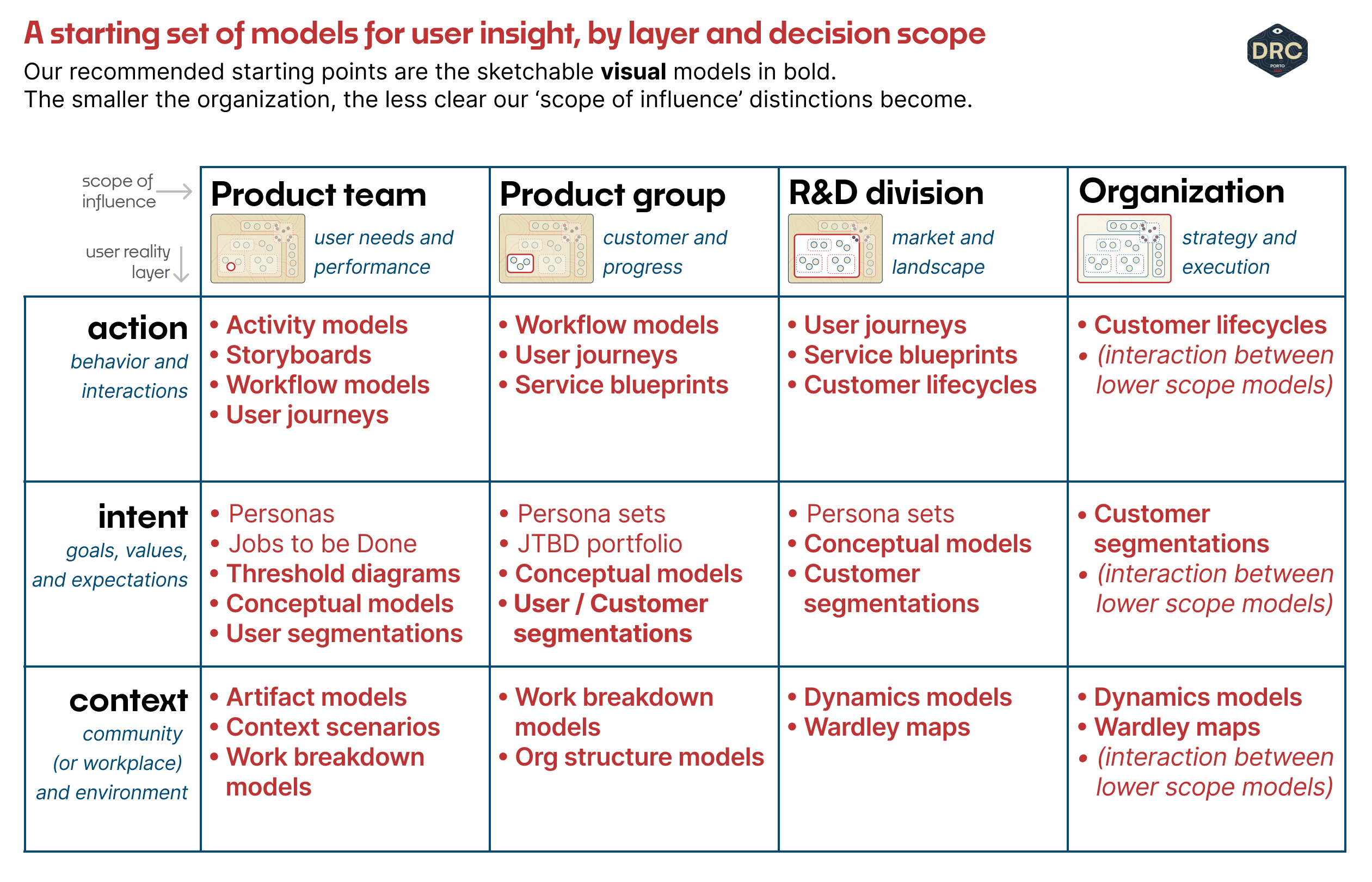
The left side of the chart below — action, intent, and context — are the same three layers we developed in Growing Research in Product Organizations, and they help us talk about what each model is trying to model. In general, in smaller scales (on the left) we start at the layer of action and then move down, and at larger scales (on the right) we start at the layer of context and move back up.
We lay out four scopes of organizational influence each model might need to work within. For most organizations over 150 or 200 people, up to thousands, some flavor of this team < group < division < organization hierarchy will exist. Your organization's reality may be more compressed or more expanded than what we find here. What will hold is that there are some models (e.g, discrete activity models detailing how users interact with a touchpoint) that are much more useful for smaller-scale decisions made within teams, and others (e.g., lifecycle models that depict how and when customers move through different stages of product use) that are much more useful for higher-scale divisions suited to product lines or divisions.
This mode of research we discuss here — identify a model, scan for existing understanding, progressively deliver further fidelity of insight through external inquiry — succeeds if and only if our understanding of the user reality co-evolves with the product effort itself.
Research effort must be integrated into the day-to-day fabric of the team's shared understanding: a model that gains fidelity when the designer needs it is useful; a model that draws out key distinctions when the engineering team must make decisions is useful; a model that helps to frame competing options when the product team must decide is useful. A model that doesn't, can't, or won't is a wall decoration, and I've made my fair share of them, unfortunately.
Worked Example: Research at Cephalopod, Inc.
We're working with a hypothetical B2B product company called Cephalopod Inc., which sells a project management tool to software development organizations. Cephalopod Inc. is a series B startup, building a product that connects to all of the companies existing knowledge sources, issue trackers, and communications streams to visually map and connect otherwise-invisible complexity.
At this stage, the organization might look like the diagram below, with a focus on the R&D division (or Eng & Design org, or PEMDA, or the PDE division, whatever you might like to call it,) with the rest of the org as a fuzzy caricature.
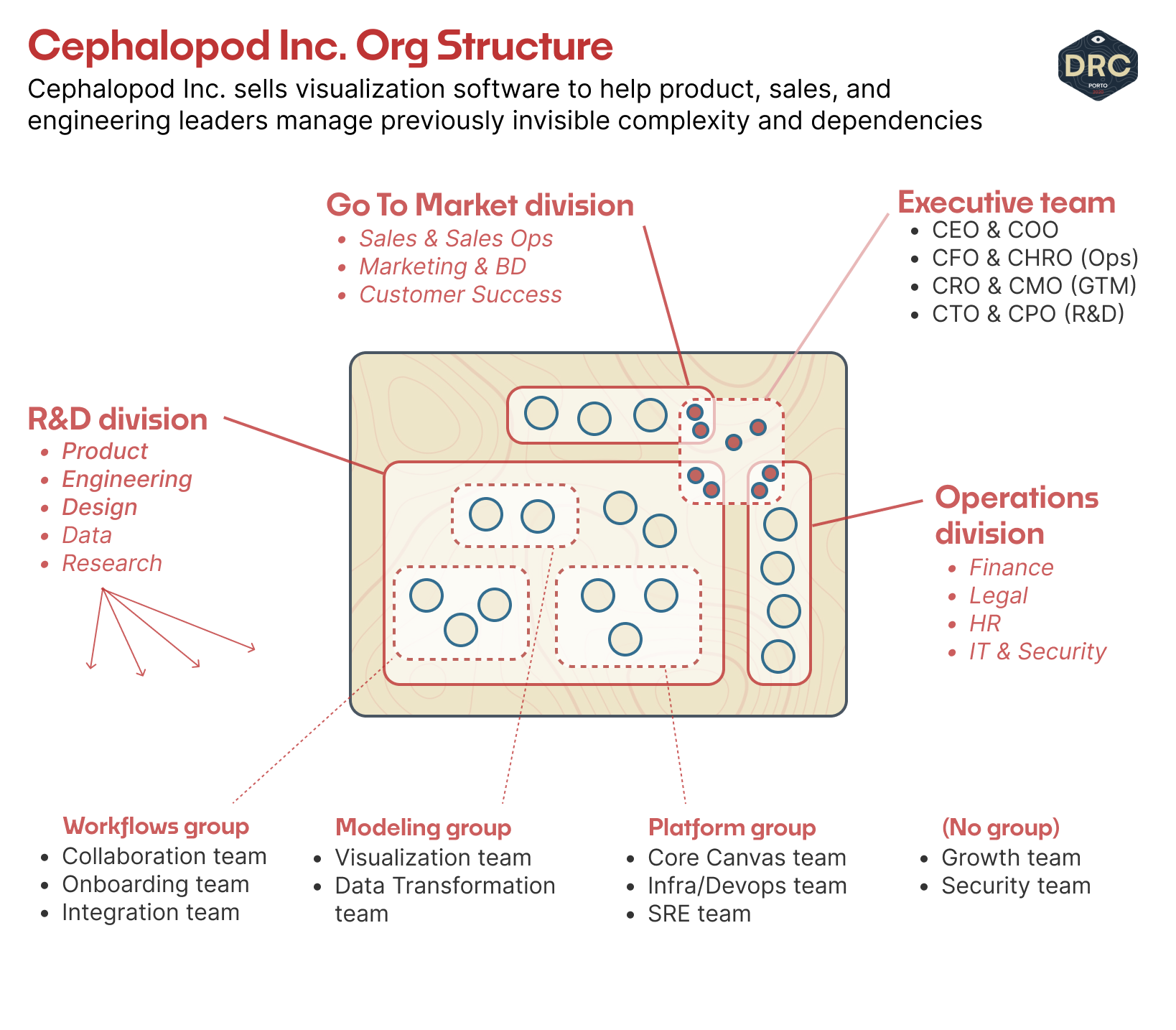
As we scan through the various levels of scale — as our research efforts target different areas of the org for partnership — the question is simple: what do the people doing work at this level of activity need to know to make good product decisions? And what do they already know, or believe is true?
We begin by understanding existing understanding: we create some set of user or competitive landscape models that correspond to existing product work at a fat-marker level of fidelity, and use these as the hooks for detailed inquiry and exploration of the user landscape.
Product Team Work: User Need & Performance
Let's start with the product team. We're working, specifically, with the PM of the Collaboration team in Cephalopod's Workflows group, and have started to join the weekly cadenced team rituals to get a feel for ongoing and upcoming work and to figure out where we can help push the team forward.
The primary focus of the Collaboration's team work right now is sharing and commenting within the same organization. There are rudimentary sharing capabilities, but no distinction between different roles or kinds of viewers and commenters — the team is looking to invest here in order to update their product offering's pricing model for creators/editors and viewer/commenter tiers.
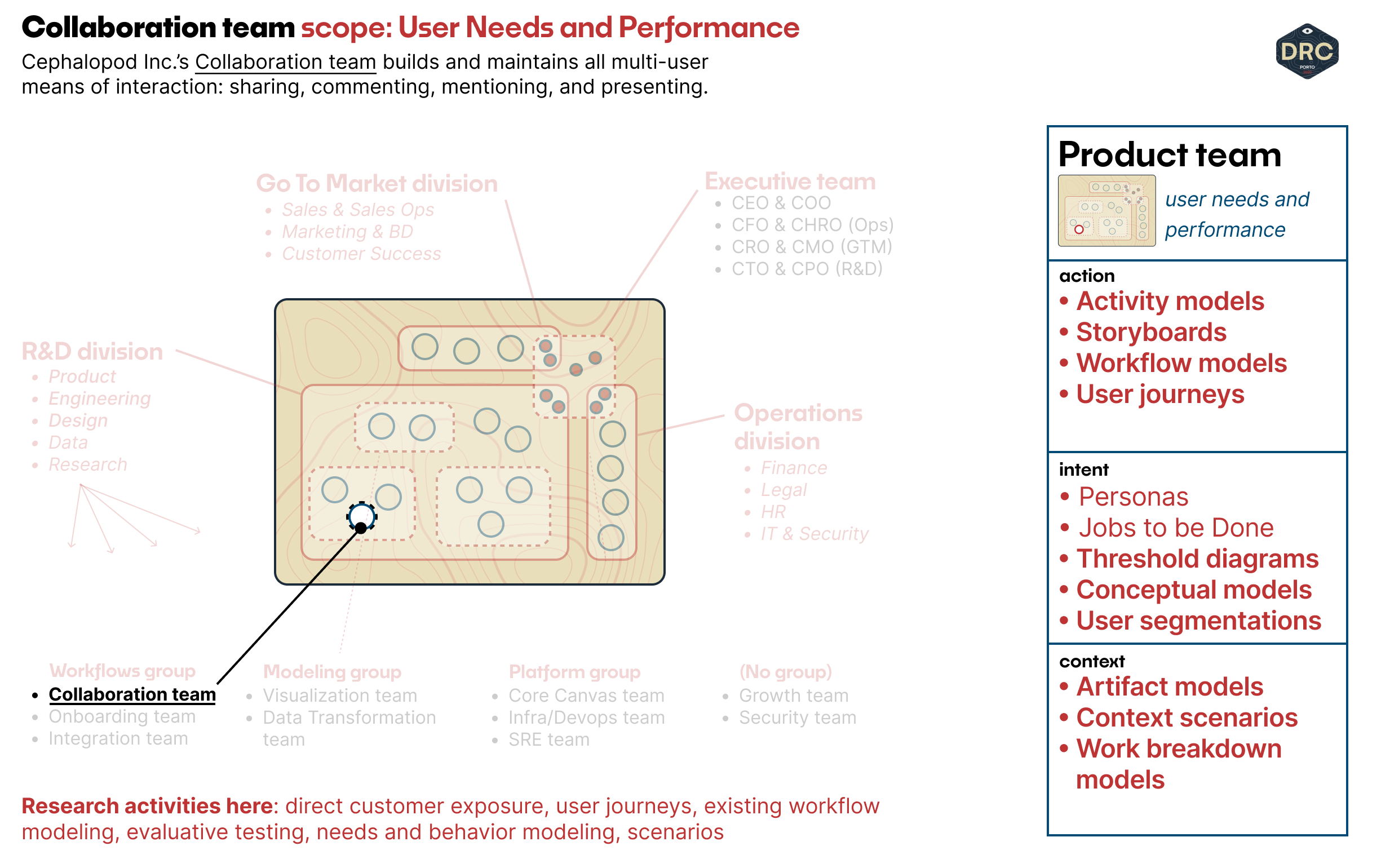
One of the first things we find is that the team hasn't visualized or built out their understanding of the step-by-step workflows that move between different users when they're sharing and commenting right now. This understanding is crucial: how do you build a useful next-iteration of sharing and commenting without a working understanding of what's going on in the current state?
The first model we can propose to work from, at the action level in this product team scope, is a simple activity model. Because this is product-facing knowledge, even as users act on it, it's fairly easy to build the first picture from internal understanding and start to highlight the existing hotspots and challenges by marking up that diagram. Perhaps our first revision of the activity model is just a simple sketch in Miro or Figjam, and after the team has agreed it's fairly representative, we augment the first iteration and annotate with user problems directly on the diagram. In a world where the team is co-located, it could look something like this:

Speaking to the designers, we also realize that the team doesn't have a clear picture of the conceptual model of sharing they want to work with. Once a visual canvas is shared with other team members for comments — how does it work? Do all shared documents add a pointer into a personally organizable view, like Google Drive? Can shared canvases be forked and duplicated into multiple views? (These straw-man questions are a little difficult because Cephalopod isn't real — but these kinds of challenges for multi-person document sharing are appropriately representative of the kinds of challenges the team will need to solve.)
Now we look at the intent layer of the product team scope and decide that a custom conceptual model might be the best vehicle to push the team's work forward. Here we can work with the designer and sketch some thumbnail models, to start. If we can agree with the team that these models are potentially useful competing options for interaction, we can take them out into the world — our next step for further fidelity will be to bring these artifacts themselves into user interviews and learn how users interpret and understand them, and then ask users to interpret their current workflows through each of the modeled lenses.
In each case, rather than the result of a research process, the models offer a tangible, discussable, and in some cases testable starting point for driving the team's work forward on their sharing features.
Product Group Work: Customer & Landscape
Now we scope up: if we're looking to work at the product group level, we're likely working with a trifecta of PM, Engineering, and Design, or at least one or two functional leads who are a part of this group.
The Workflows group owns all the pathways of user activity in the group: the Collaboration, Onboarding, and Integration teams. One of the big challenges at the group level is to coordinate, balance, and prioritize the work across the underlying product team, and make sure they're building towards a larger mission that enables a specific group or segment of customers.
For Cephalopod, these users are likely Product Managers visualizing product release dependencies, engineering managers visualizing ongoing work and systems dependencies, and a mix of other stakeholders who might need to consume or comment on these visualizations (organizational leaders, internal partners to the team, or even vendors or external partners.)
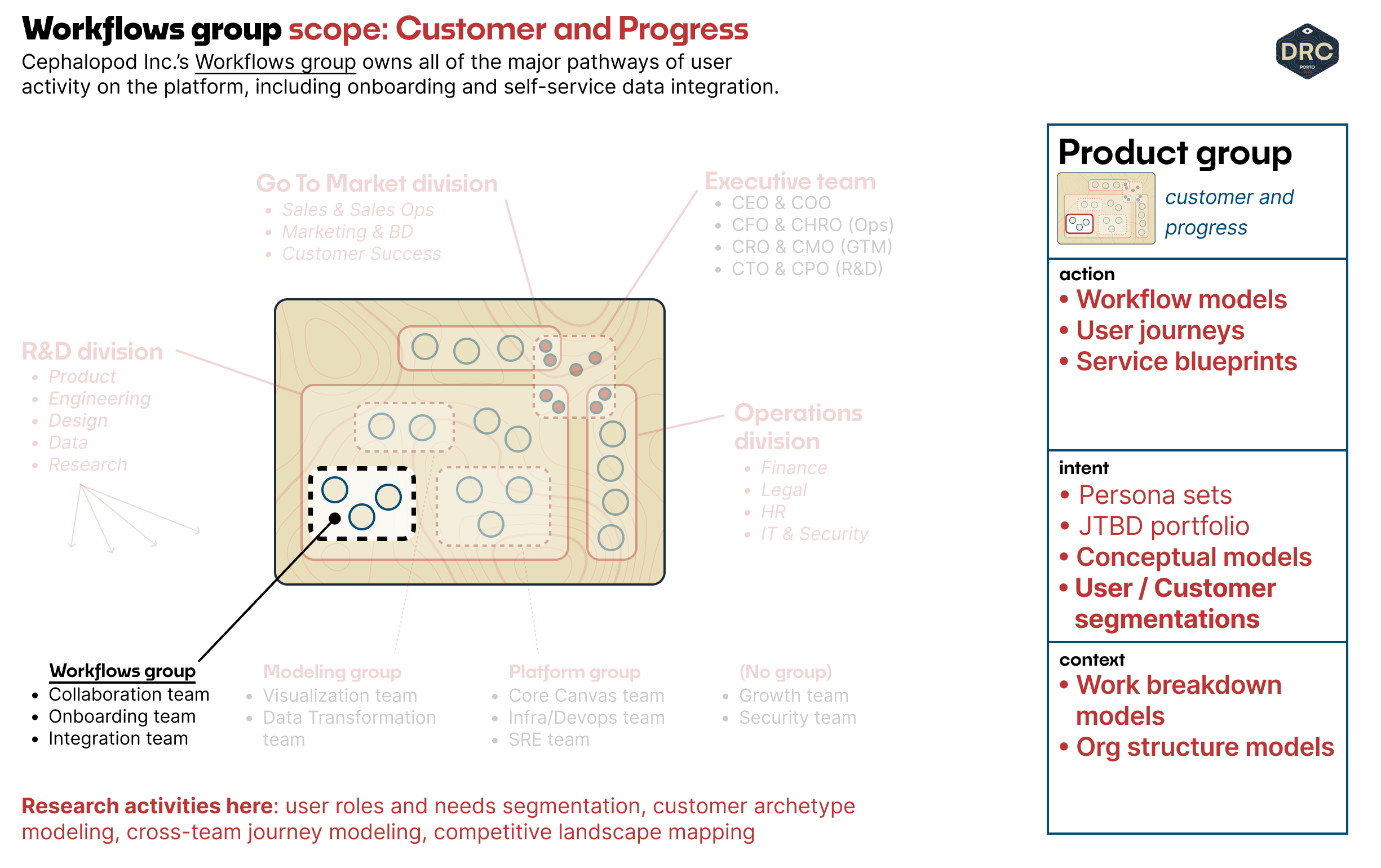
If we're talking about users working together, we want to make sure we have a grounding in how their work relates to their existing organization. And a crucial starting point for that is to be clear on which users we're talking about and prioritizing.
As a starting point for the product group level, we decide to start with a simple org structure model from the context layer. Working with the three leads and one of our key sales partners, we draw out an internal view that shows the roles of users who may be working with our product and highlight the ones who are most important to us.
The first sketch, as always, is on paper (in person) or something like a Figjam/Miro board (remote). We build our sketch, highlight key users, and work with the team to make sure there aren't any potential relationships between users, constraints, or role types that we're missing. After collecting insight into these user roles and interactions through a set of pre-existing customer interviews run by the Collaboration team, our 2nd iteration of the model could look like this:
That's enough to get us started and contextual who and why might be receiving, editing, or commenting on the various documents, and a simple artifact we can bring in to explain our decisions and justify the work as we share with team members in the larger organization.
The other crucial piece, when we know who we're talking about, is how the information actually flows between those team members. Here it's clear we're working with the layer of action, and our starting point is a workflow model that highlights how interaction moves between the roles we've already identified.
R&D Division Work: Market and Landscape
The divisional scope takes us out to a higher scope where we have to pay attention to the competitive market and forces at play in the larger landscape. Cephalopod is at a point where the entire division is looking into multi-org sharing: customers working internally is the scope of product groups and product teams; customers working with outside organizations and partners is an emerging need that the entire division must understand how to grapple with.
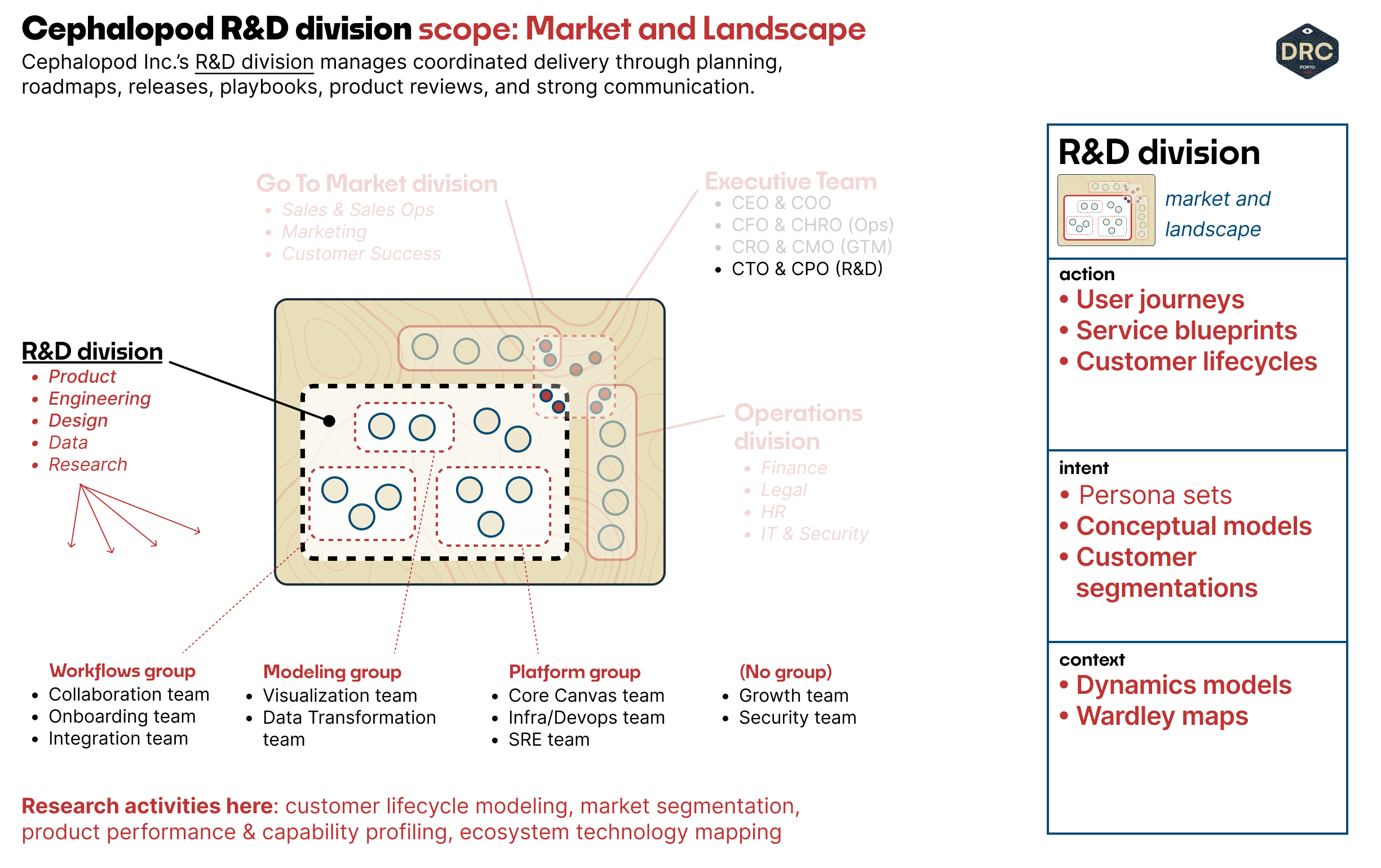
Once we start inviting different people from several organizations to Cephalopod projects, role distinctions become even more important. A partner executive does not need the same kind of notifications and updates that a member of the working team does, but right now they're invited and notified with the same level of noise as regular project members... and if there's one thing executives won't put up with, it's noise in their inbox.
To figure out what kind of role distinctions we might need to instantiate, we have to figure out with the team what kinds of roles we're dealing with. We might start with a customer segmentation that builds on our lower-level org structure, working at the layer of intent.

Once we know who we're dealing with, and what their scope of concern is, we also need to determine how they're involved in projects. Here, we can take our updated customer segmentation and build out a customer-lifecycle model for those different groups, looking at their scope of participation and interest across a Cephalopod product.

Organizational Work: Strategy & Execution
Finally, we'll look out at the organizational level of scale. What does the Cephalopod strategy look like, and where do they invest in the underlying technologies and capabilities that power their product?
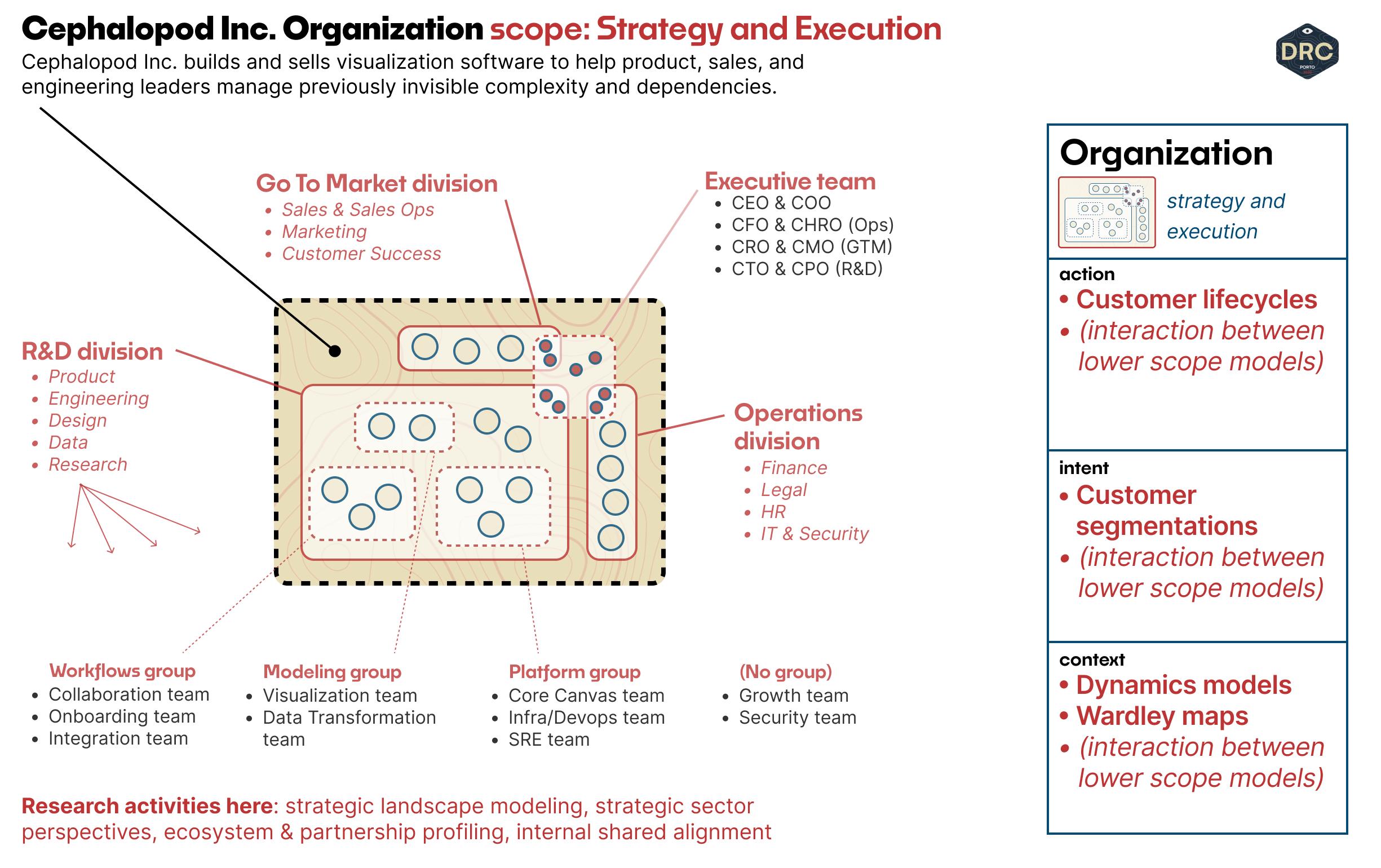
The best tool available here, I believe, is Wardley mapping. They assume that all technologies evolve, and help us understand the evolutionary characteristics of the different technologies that ladder up to support customer needs.
In the same way that we started our prior work, we can get key decision-makers and leaders in the room, and profile the technology stack we're using, how well-evolved those capabilities are, and how we might like to treat them, like build vs. buy decisions, and understanding where to invest in new capabilities we predict will emerge.

Wardley mapping is a huge topic in its own right — beyond modeling visually the technological landscape, the framework carries implications for how the organization might be structured, and which postures of development different teams should take. For example, should a given scope of investment be an agile effort to explore new capabilities or an expected kind of capability that should focus on performance and stability closer to a six-sigma approach?
Working with Wardley maps is, right now, the high culmination of organizational strategy — they're not just visual models but maps where space has meaning and the position of each element implies specific kinds of actions and activities. One of my qualms with the Playing to Win framework for strategy is that it asks us to define "Where to play" but doesn't offer any kind of visual reference or landscape features we should be aware of to choose the "where." Wardley maps (in conjunction with the user needs identified in customer/market segmentations) offer us a literal map, so we can point out where to play and identify the strategic forces that affect our decisions. But more on that next time...
As always, the method itself is not our concern, but how the understanding developed by this method feeds into the strategic decision-making processes at this level of scale. The process is where the power lies. In that sense, these methods are interchangeable pieces of our ongoing processes of observing, orienting, deciding, and acting — over, and over, and over again.
Strategic implications
In some ways, we're trying to expand and operationalize the same kind of approach that Claire Menke outlined in 2017, with her Goldilocks Experience of Developing a Foundational Research Framework (see also her talk).
Here, we accept Claire's novel approach as a known and expected practice. We move from a custom-built mix-and-match to accepting that there are known and expected kinds of models [for a given scope of product work], and it will take a set of them, likely multiple, to appropriately contextualize and ground the product work at hand.
Now, imagine what happens if this kind of understanding is the default starting point for research that's tightly aligned to product work.
Unbundling research: from projects to progressive iteration
Formal projects tend to start with a specifically scoped research question. I used to think like this — the core model I've used for years to understand the research process in The Researchers Journey begins with identifying productive questions. Our approach here looks for an area of action, intent, or context and some notion of how we'll model what's important there.
Question co-evolve along with our understanding, and guides those elements and factors selected in building models. Thinking in this iterative and adaptive mode of research is one way to better align our work with the pace and direction of product development and cadenced customer discovery activities.
Research, set up in a project mode, tightly scoped to a question, and proceeding forward in isolation from the team (or group, or division) who are going to work with its outcomes, is a difficult undertaking. Especially if that team or group has some existing cadence of customer contact or discovery work. The team's shared understanding evolves as a function of its communication and delivery cadences, which are often far faster than any formal research. Worse yet, the reality and fundamental assumptions on which a research project was based can change on a month-to-month or even a week-to-week basis for some modes of product teams.
When we think about research activities as streams of accretive and ongoing synthesis, paced according to existing modes of customer contact and interviews, we can examine and scope our activities quite differently than single project units. For example, we may be working with the Cephalopod Collaboration team on a user activity model for document sharing, while also working with the Workflows group on user role segmentation and a workflow model that shows the scope and interaction of different product teams' capabilities.
For each model, new insights and questions are added as the work evolves, and it's consolidated and re-synthesized into the next form after some critical amount of user and customer insight (a big revision every 3–5 interviews, for example.) While we can't predict when it's really "done," much like research projects we have some idea, given the ambition of our scope, how much more we may need to see to get a useful picture.
- Collaboration team, Activity model: imagine that we've got a roughly-good picture after 7 interviews, but we'll want to speak with 6–7 more users to look for deeper patterns or inconsistencies.
Status: 7 more interviews this cycle (any user role engaging in Sharing). - Workflows group, User segmentation model: imagine that we've built this picture after speaking with internal SMEs and 6 customers across 4 roles. We're fairly confident in the model and its implications, but we'll want to speak with one more customer from each role to further refine our understanding of their work boundaries within-and-across organizations.
Status: 4 more interviews this cycle (1 per Workflows-group key role). - Workflows group, User workflow model: finally, imagine that we've got the slightest understanding so far of cross-product user workflows for this group, built on internal expert interviews and 2 customer conversations so far — we'll need a couple of good revisions and probably need to discuss this picture with at least 10 more users.
Status: 10 more interviews this cycle (mix of Workflows-group key roles).
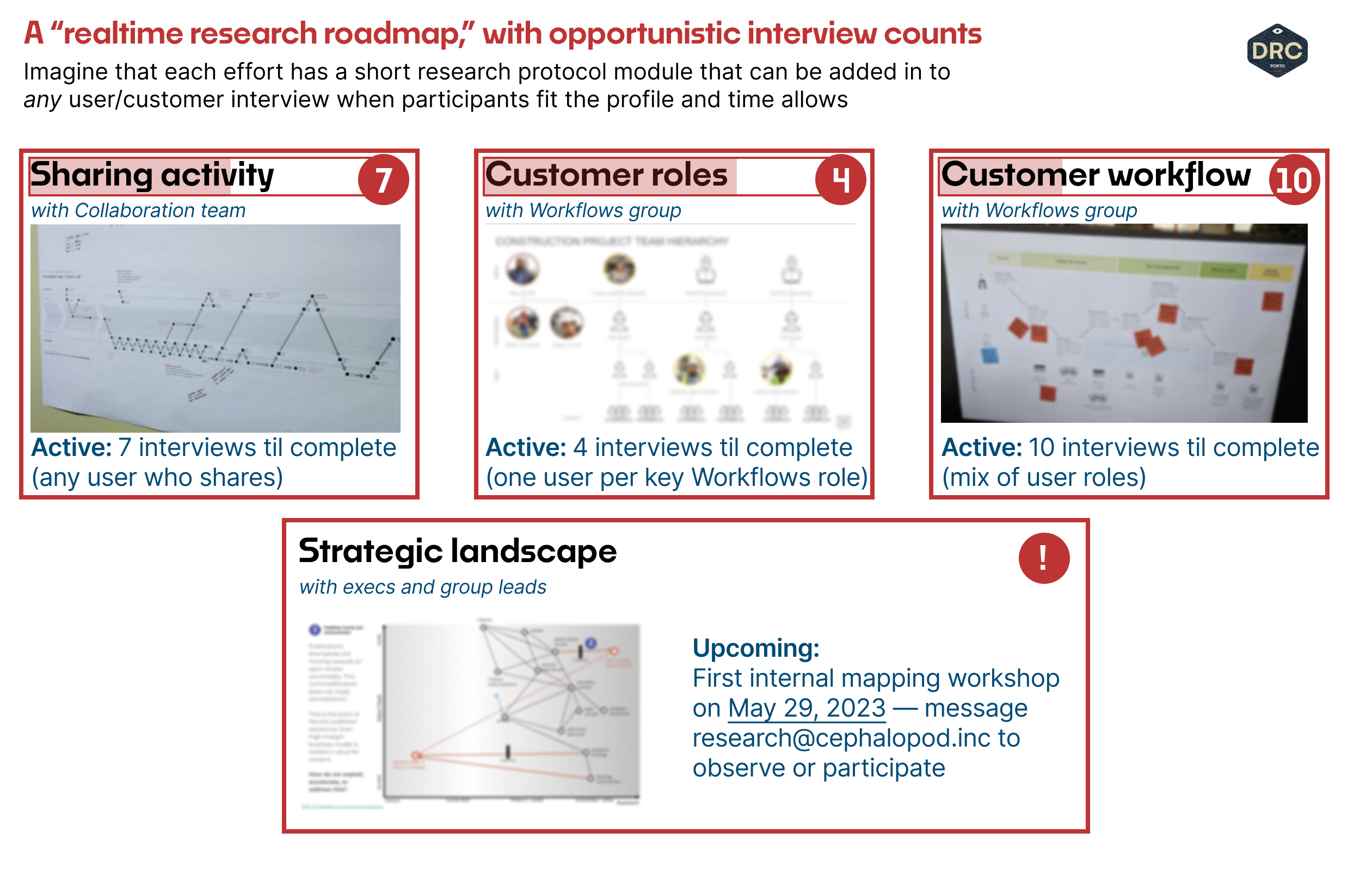
The trick here is that rather than view our research efforts as single-stream projects, we can view them as a collection of efforts that opportunistically feed into ongoing models. We might, for each model, build a short interview protocol module that can be dropped into any existing user interview or customer discovery call so long as there's time and our participants fit our profiles. It keeps the research lean and allows for simple course corrections in the face of product thrash: adjust the interview protocol, spin out a new model, and identify a specific area that requires focused attention and investigation.
At the least, we don't "go bust" if a research project is deprioritized or canceled, there's already a trail of understanding we can use if we move down this path in the future: we re-consolidate and snapshot any given model before retiring its work stream, and move on.
Cascading models and re-orienting research repositories
How research and insights are typically stored is also primarily hooked into projects. This is a simplistic view, as the facets and factors by which research is stored, tagged, and made accessible are quite wide-ranging; but it speaks to the limitations of moving between and across different research efforts.
How is our insight connected? How can we understand the connections and tensions between what we learn in one area versus another? I believe, once again, the ultimate answer will be visual.
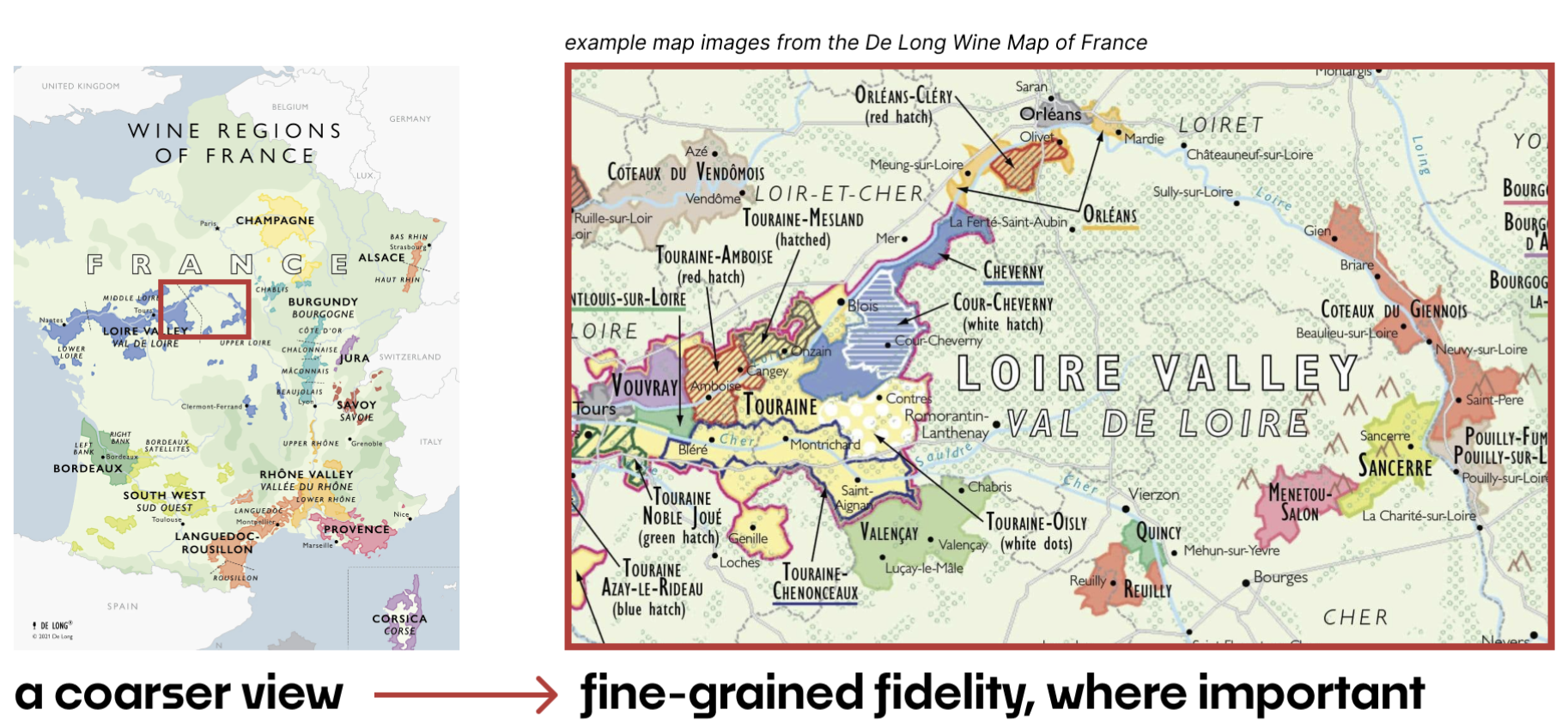
A benefit of visually structuring our understanding through models is that their connections are apparent through the very structure and elements of the models themselves. We can link our models just like a map callout can highlight where the next layer of fidelity lies, and "link" to it, visually.
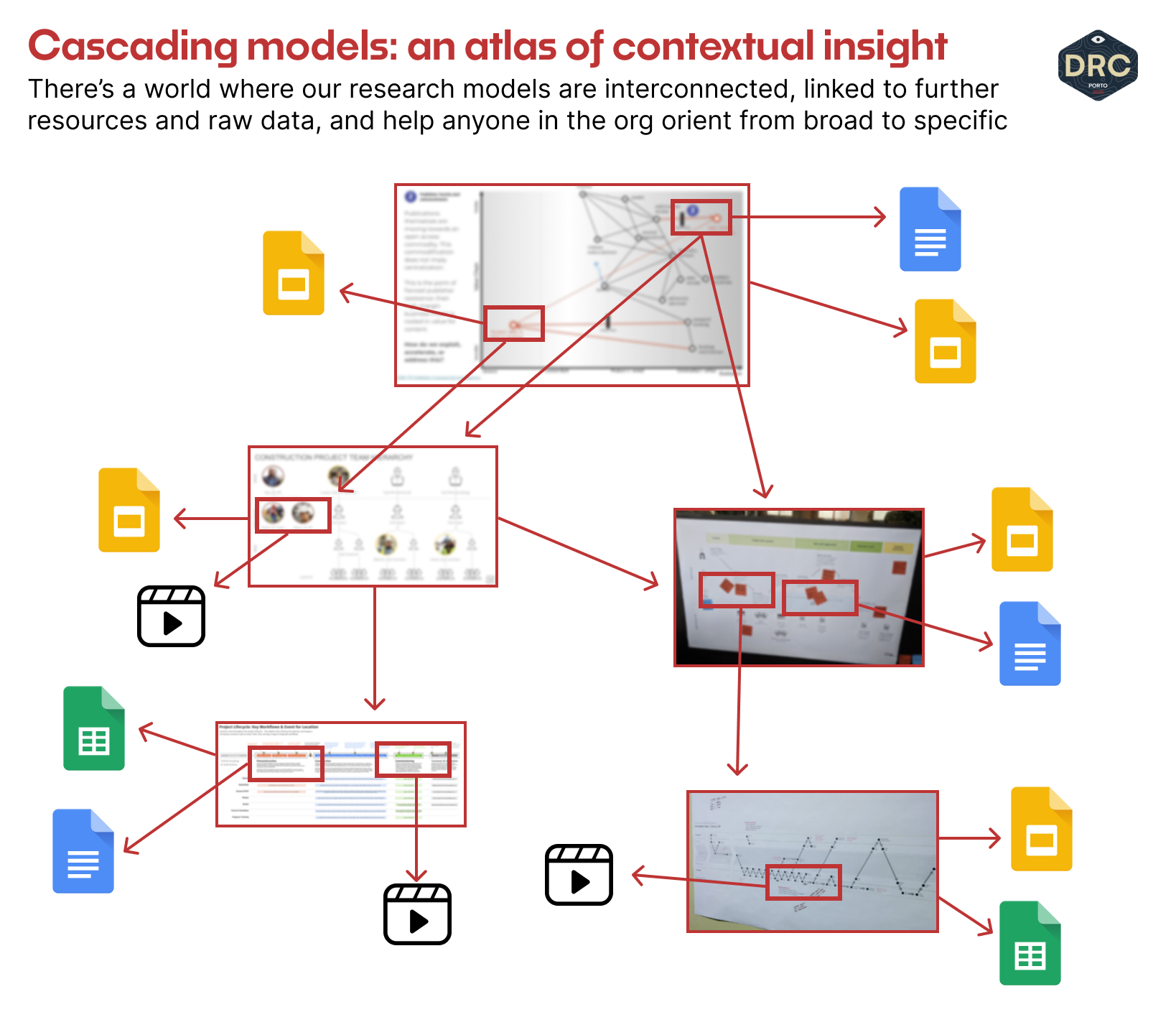
There is a beautiful future where team members getting up to speed don't need to dive through written reports and tagged insights but begin from a visual atlas of user insight that's fully connected, updated in realtime, and links out to the reports, details, or recordings that matter, from the context of the models we use to contextualize those things. We're a bit far out here, and I imagine that as these models move into accepted, commodity forms, our ability to link them together and productize their connections is the next step of evolution in vendor tooling and research repositories.
Next Up
What do you think? I'm happy to hear it and would it love if you can share this perspective with our product, design, and research colleagues who may find it helpful. If you haven't already, consider subscribing to this newsletter.
Through my consulting projects, I'm still exploring what it means to work in this mode, and I would love to hear from you if you've also been moving in this direction.
Next time, we'll take a look at how to understand and work with one of my favorite models to date — Simon Wardley's Wardley Maps — or perhaps follow up on other topics here first, depending on the questions that arise.
This is part of an ongoing exploration into research as it co-evolves with product practices and re-integrates into the organization.
For weekly thoughts on the nexus of products-organizations-process-strategy, and updates on larger resources like this, consider joining my newsletter.


